یه سوال مصاحبه طراحی سیستم داریم که توش باید یه ابزار کوتاه کننده URL مثل TinyURL یا Bitly رو از صفر طراحی کنیم. همه چی رو از الزامات طراحی و معماری و طراحی اجزا تا اینکه چطور میشه سیستم رو برای سرعت بالا و امنیت بیشتر ارتقا داد، بررسی میکنیم.
اول از همه باید مشخص کنیم که این سیستم چیکار باید بکنه و چیکار نباید بکنه.
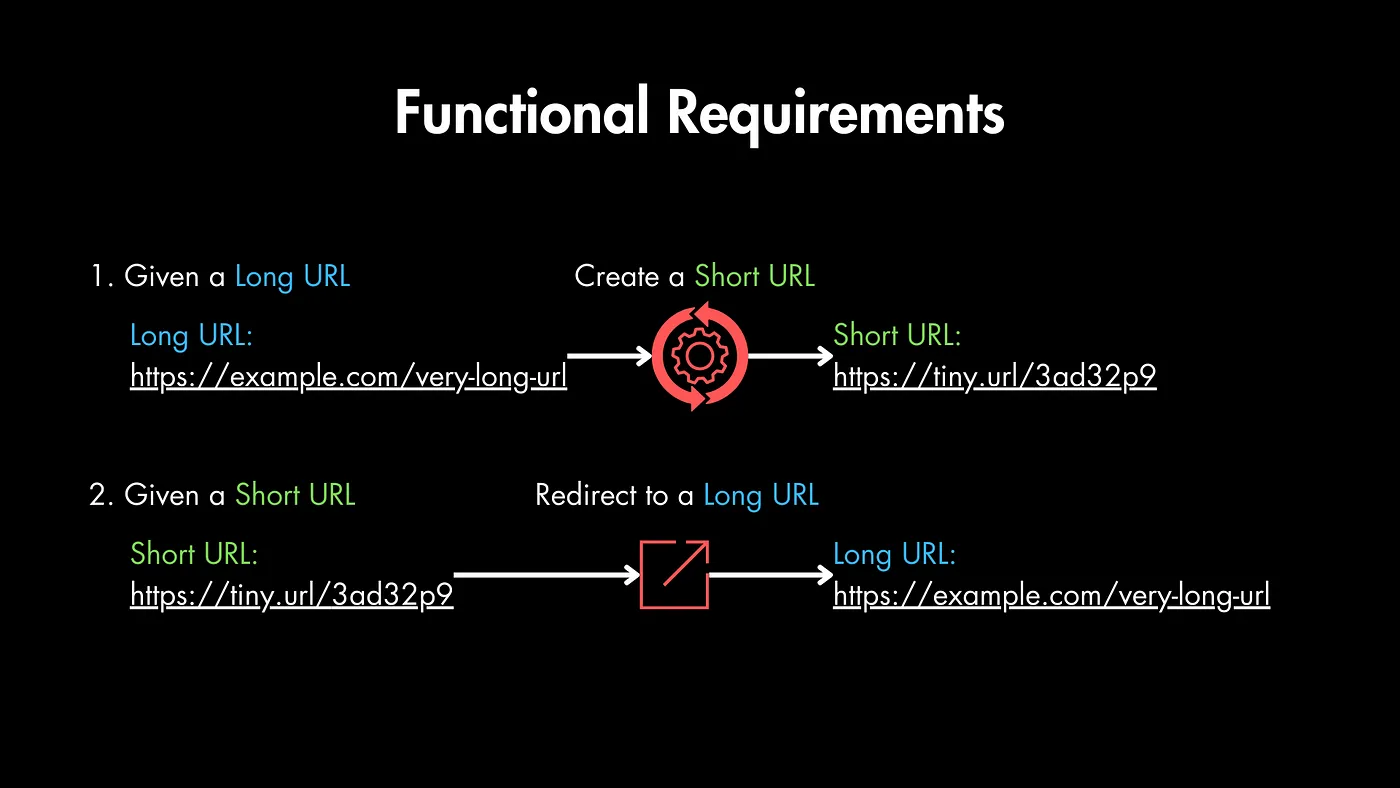
از نظر کارکردی، دو تا وظیفه اصلی داره:
- وقتی یه URL بلند بهش میدی، باید یه URL کوتاه بسازه.
- وقتی یه URL کوتاه بهش میدی، باید کاربر رو به URL بلند ببره.
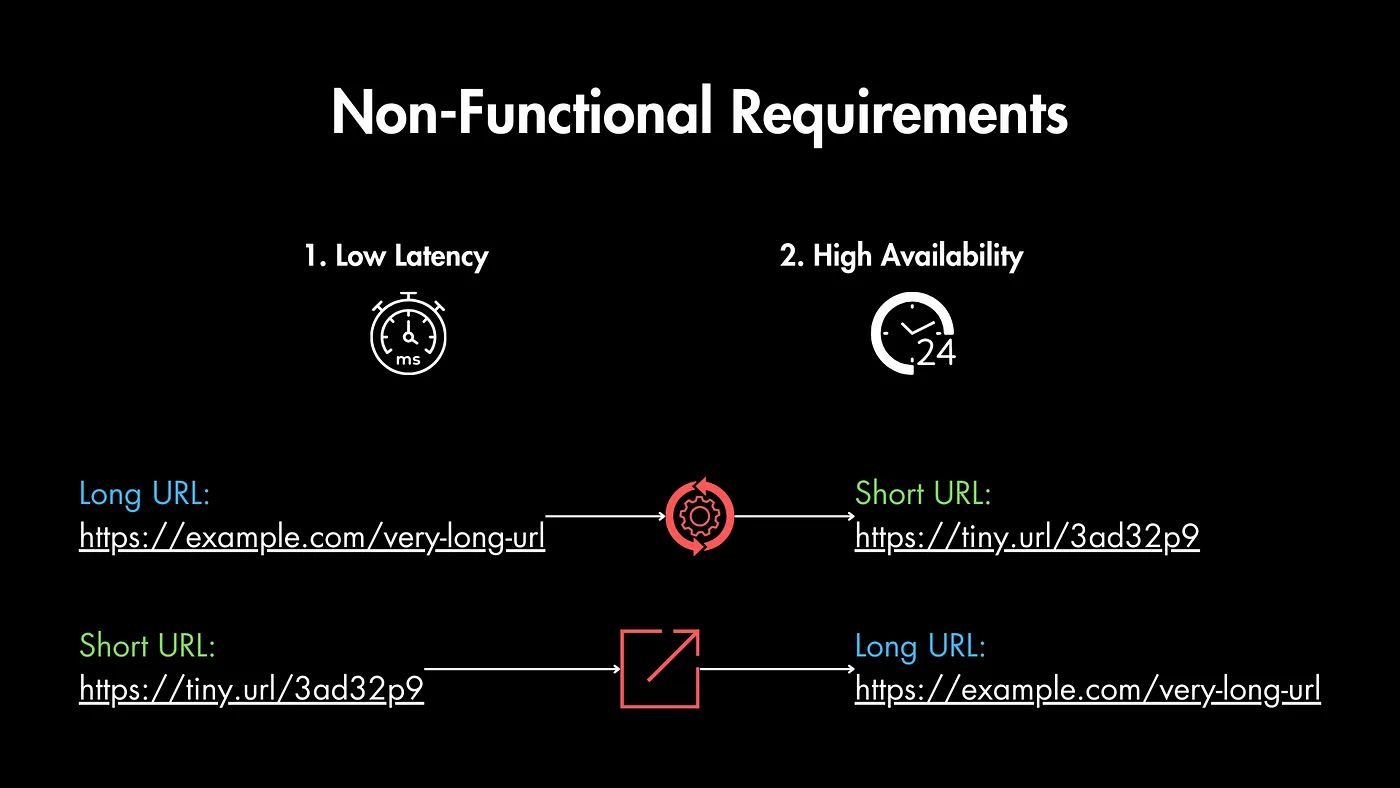
 برای این سرویس دو تا چیزه خیلی مهمه: اینکه کارش رو خیلی سریع انجام بده (پاسخهای کوتاه) و اینکه همیشه در دسترس باشه (همیشه آنلاین). میشه گفت اولویت با این دوتاست.
برای این سرویس دو تا چیزه خیلی مهمه: اینکه کارش رو خیلی سریع انجام بده (پاسخهای کوتاه) و اینکه همیشه در دسترس باشه (همیشه آنلاین). میشه گفت اولویت با این دوتاست.
 سوالات شفاف سازی برای مصاحبه کننده
سوالات شفاف سازی برای مصاحبه کننده
اینجا چند تا سواله که برای شفافسازی از مصاحبهکننده میتونیم بپرسیم تا مطمئن بشیم در مورد مقیاس سیستم همنظر هستیم:
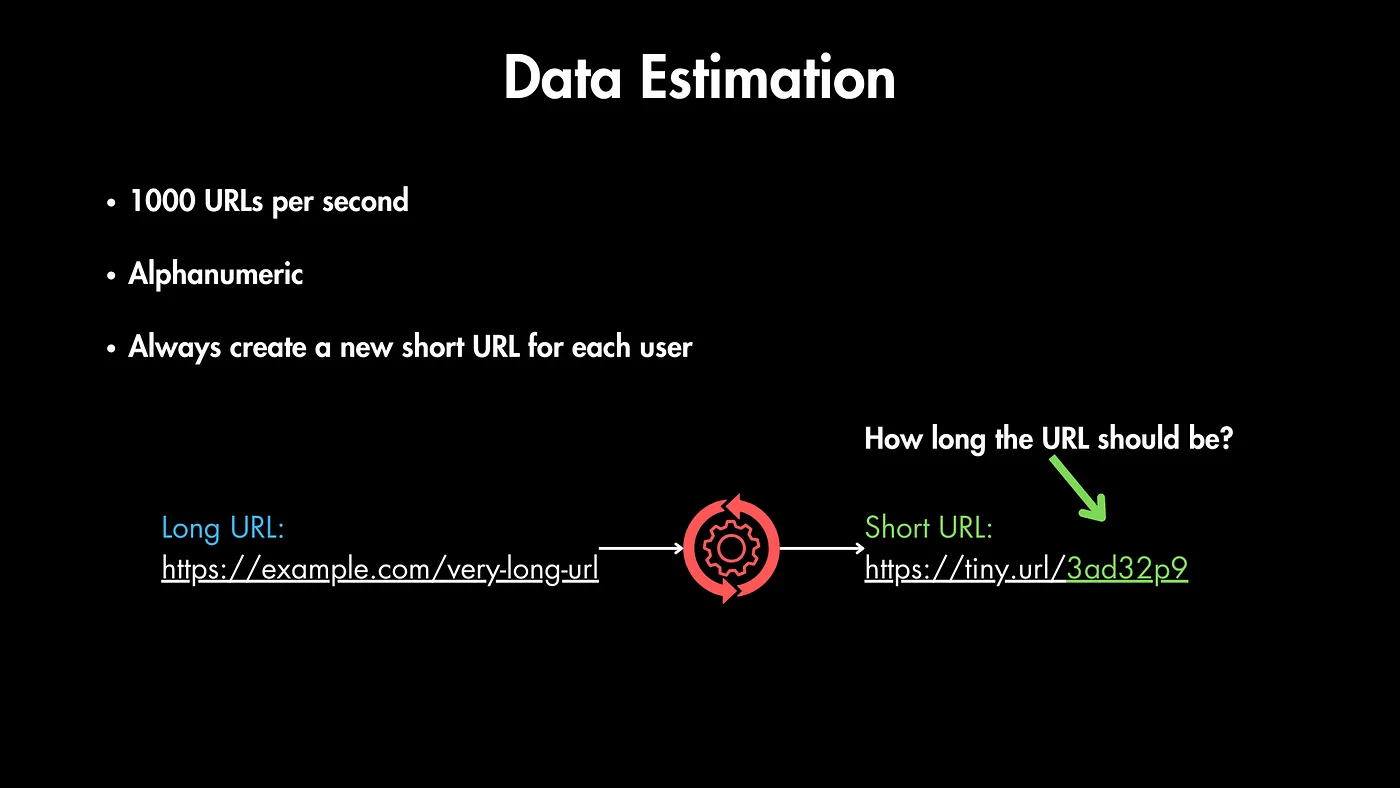
استفاده: تقریباً چند تا URL باید در هر ثانیه کوتاه کنیم؟ (فرض کنیم ۱۰۰۰ تا)
کاراکترها: میتونیم از اعداد و حروف (الفبا-عددی) استفاده کنیم یا نمادهای دیگه هم میشه؟ (فرض میکنیم فقط الفبا-عددی)
منحصر به فرد بودن: هر بار که یه URL بلند وارد میشه، یه URL کوتاه منحصر به فرد بسازیم، حتی اگه چند نفر همون URL رو وارد کنن؟ (تو این طراحی، بله)
تخمین: محاسبات اطلاعاتی
با این اطلاعات، باید محاسبه کنیم که URL بعد از کوتاه شدن چقدر باید باشه. قطعا میخوایم تا حد ممکن کوتاه باشه، ولی باید تعداد URLهایی که هر سال ساخته میشه رو هم در نظر بگیریم.
اول، بیایم تعداد URL های منحصر به فردی که برای یه دوره زمانی قابل توجه لازم داریم رو تخمین بزنیم. یه روش رایج اینه که حداقل برای چند سال کارکرد سیستم برنامهریزی کنیم. برای سادگی، بیایم برای ۱۰ سال محاسبه کنیم.
تعداد ثانیه در یک سال: ۶۰ ثانیه/دقیقه × ۶۰ دقیقه/ساعت × ۲۴ ساعت/روز × ۳۶۵ روز/سال = ۳۱۵.۳۶ میلیون ثانیه
کل ثانیه های ۱۰ سال: ۳۱۵.۳۶ میلیون × ۱۰ = ۳۱۵.۳۶ میلیارد ثانیه
کل URL های ۱۰ سال: ۱۰۰۰ × ۳۱۵.۳۶ میلیارد = ۳۱۵.۳۶ میلیارد URL منحصر به فرد
این یعنی دیتابیس ما باید بتونه در هر ثانیه ۱۰۰۰ بار نوشتن رو مدیریت کنه و هر سال هم، ۳۱۵.۳۶ میلیارد تقسیم بر ۱۰۰۰ ضربدر ۶۰ ضربدر ۶۰ ضربدر ۲۴ ضربدر ۳۶۵ = ۳۱.۵ میلیارد URL جدید ساخته میشه. اگه فرض کنیم به طور معمول ۱۰ برابر بیشتر از نوشتن، خواندن داریم، پس بیشتر از ۱۰ × ۱۰۰۰ = ۱۰.۰۰۰ بار خواندن در هر ثانیه خواهیم داشت.
حالا باید بفهمیم چندتا کاراکتر لازمه تا برای حجم ۱۰ ساله URL های کوتاه منحصر به فرد کافی داشته باشیم. با توجه به اینکه تعداد کاراکترها ۶۲ تا هست، طول شناسه URL رو میشه به شکل زیر محاسبه کرد:
- ۶۲^۱ = ۶۲ URL منحصر به فرد (۱ کاراکتر)
- ۶۲^۲ = ۳۸۴۴ URL منحصر به فرد (۲ کاراکتر)
و به همین ترتیب …

با ادامه این محاسبه، میبینیم که ۶۲^۷ (حدود ۳.۵ تریلیون) اولین مقداریه که از تعداد تخمینی ۳۱۵ میلیارد URL مورد نیازمون بیشتره. بنابراین، برای پشتیبانی از رشد پیشبینیشده در ده سال آینده، URLهای کوتاهشده ما باید حداقل ۷ کاراکتر داشته باشن.
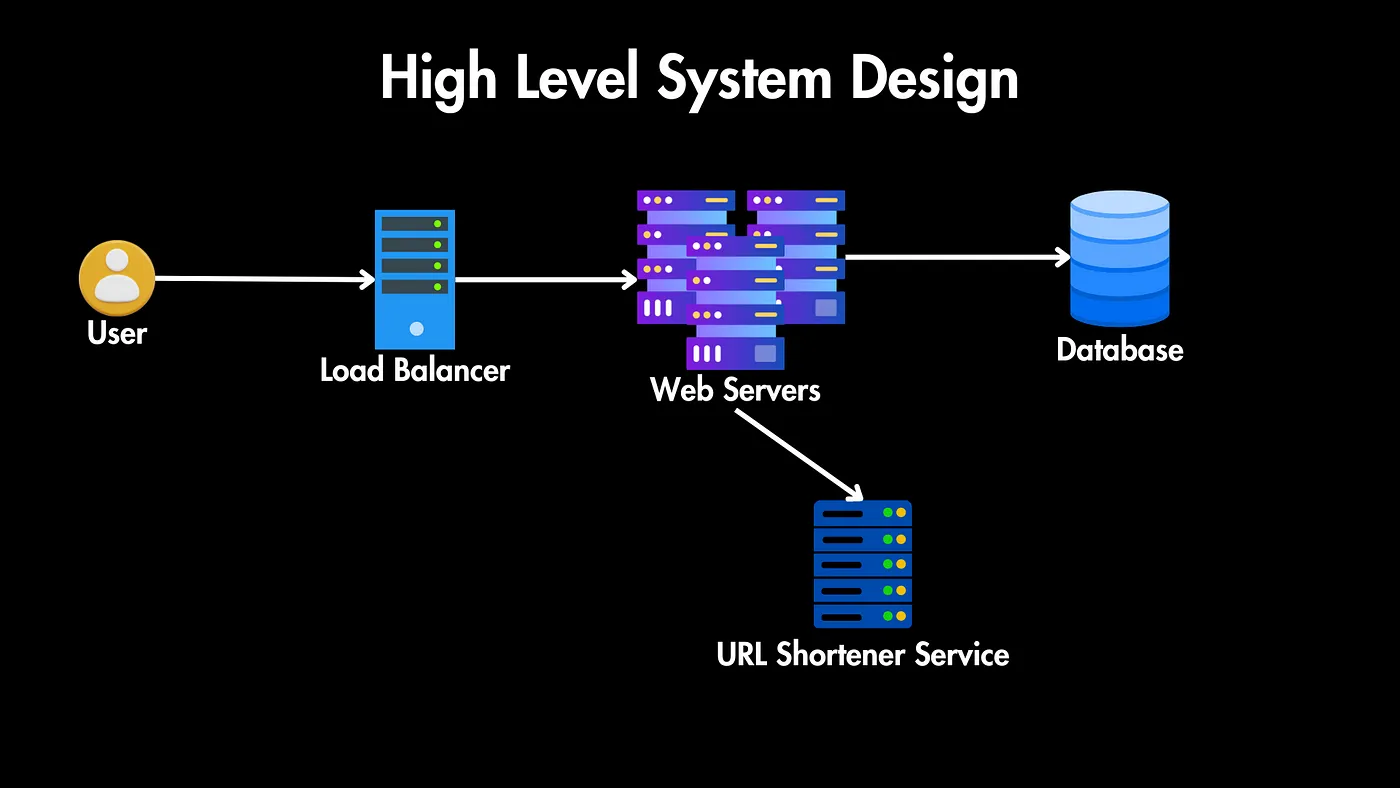
معماری سطح بالا
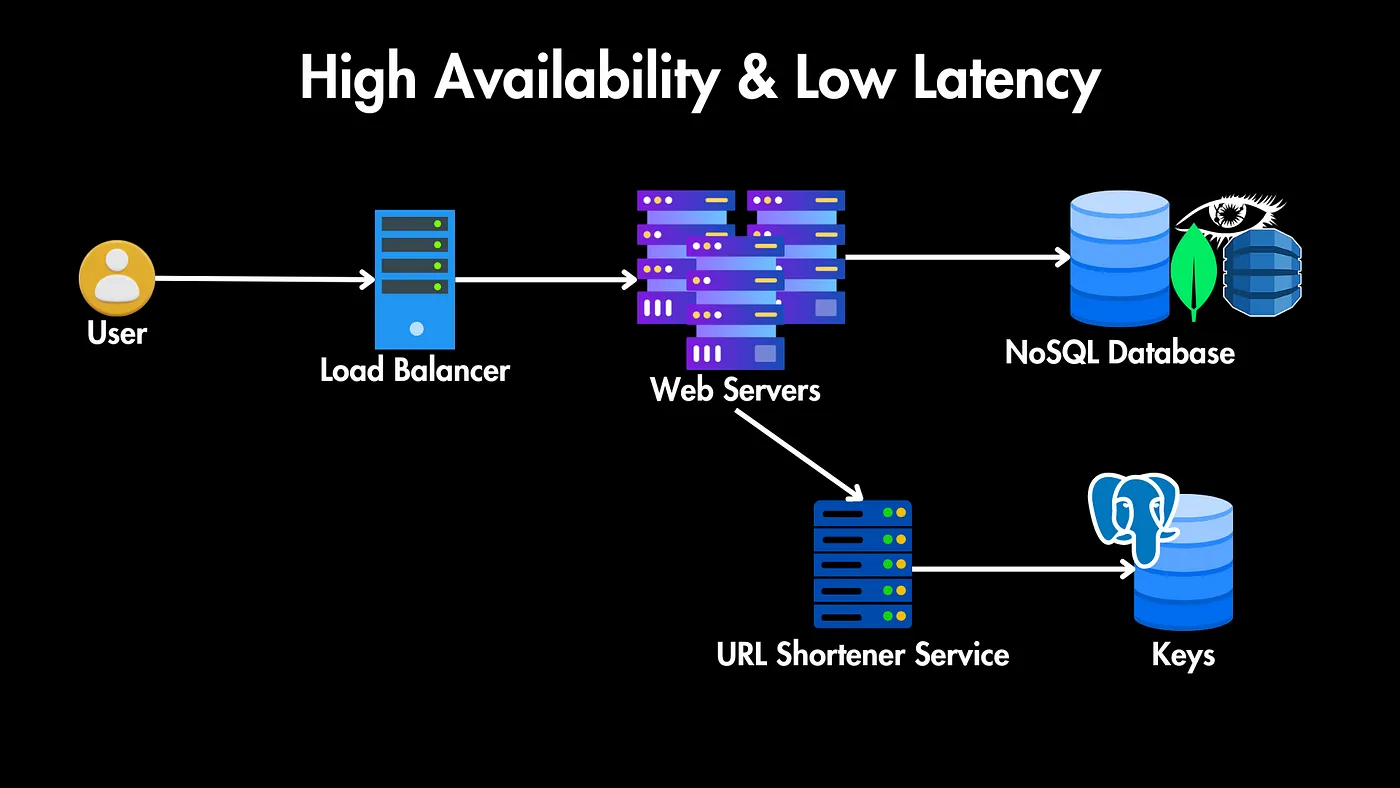
سیستم ما این اجزای کلیدی رو خواهد داشت:
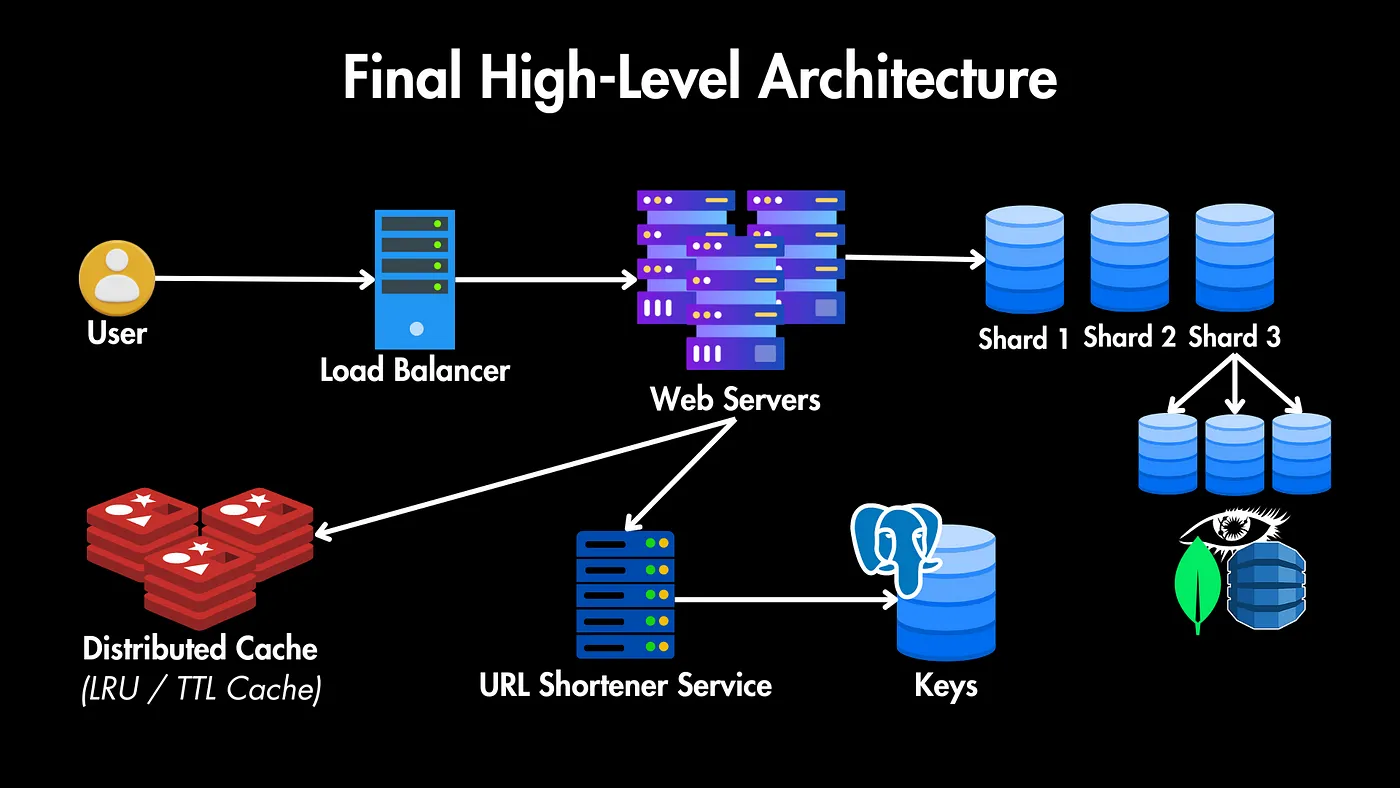
کاربران: کاربرانی داریم که URL های بلند خودشون رو برای کوتاه شدن میفرستند یا یه URL کوتاه به ما میفرستند و ما باید اونها رو به URL بلند هدایت کنیم.
توزیعکننده بار (Load Balancer): همه این درخواستها از طریق یک توزیعکننده بار عبور میکنند که ترافیک را بین چندین سرور وب توزیع میکنه تا در دسترس بودن بالا و توزیع متعادل بار تضمین بشه.
سرورهای وب: این سرورهای تکثیر شده مسئول رسیدگی به درخواستهای HTTP ورودی هستند.
سرویس کوتاهکننده URL: ما همچنین به یک سرویس کوتاهکننده URL نیاز داریم که شامل منطق اصلی برای ایجاد URLهای کوتاه، ذخیره نگاشت (mapped) URL و بازیابی URLهای اصلی برای هدایت مجدد باشه.
پایگاه داده: ارتباط بین URLهای کوتاه و همتایان بلند آنها را ذخیره میکند. قبل از طراحی پایگاه داده، باید نیازهای بالقوه ذخیرهسازی برای URLهای کوتاهشده را در نظر بگیریم.
هر URL شامل شناسه منحصر به فرد (حدود ۷ بایت)، URL بلند (تا ۱۰۰ بایت) و دادههای کاربر (حدود ۵۰۰ بایت) خواهد بود. این یعنی برای هر URL به حدود ۱۰۰۰ بایت نیاز داریم. در طول ده سال، با حجم پیشبینیشده ما، این رقم به تقریباً ۳۱۵ ترابایت داده ترجمه میشه.
قبل از اینکه ادامه بدیم، بیاید اول به طراحی API برای تک سرور وبمون فکر کنیم.
طراحی API
بیایید عملیات های پایه API برای سرویس خودمون رو تعریف کنیم. همونطور که در الزامات عملکردی گفته شد، ما از یه REST API استفاده میکنیم و به دو نقطه انتهایی (endpoint) نیاز داریم.
۱. ساختن یه URL کوتاه (POST /urls)
ورودی: یک JSON که حاوی URL بلند باشه {“longUrl”: “https://example.com/very-long-url"}
خروجی: یک JSON با URL کوتاهشده {“shortUrl”: “https://tiny.url/3ad32p9"} و کد وضعیت ۲۰1 Created.
اگر درخواست نامعتبر یا معیوب باشه، پاسخ ۴۰۰ Bad Request رو برمیگردونیم، و اگه URL درخواستی قبلاً در سیستم وجود داشته باشه، با ۴۰۹ Conflict پاسخ میدیم.
۲. هدایت به URL بلند (GET /urls/{shortUrlId})
ورودی: پارامتر مسیری shortUrlId
خروجی: پاسخی با ۳۰۱ Moved Permanently و URL کوتاه جدیدا ایجاد شده در بدنه پاسخ به صورت JSON { “shortUrl”: “https://tiny.url/3ad32p9" }
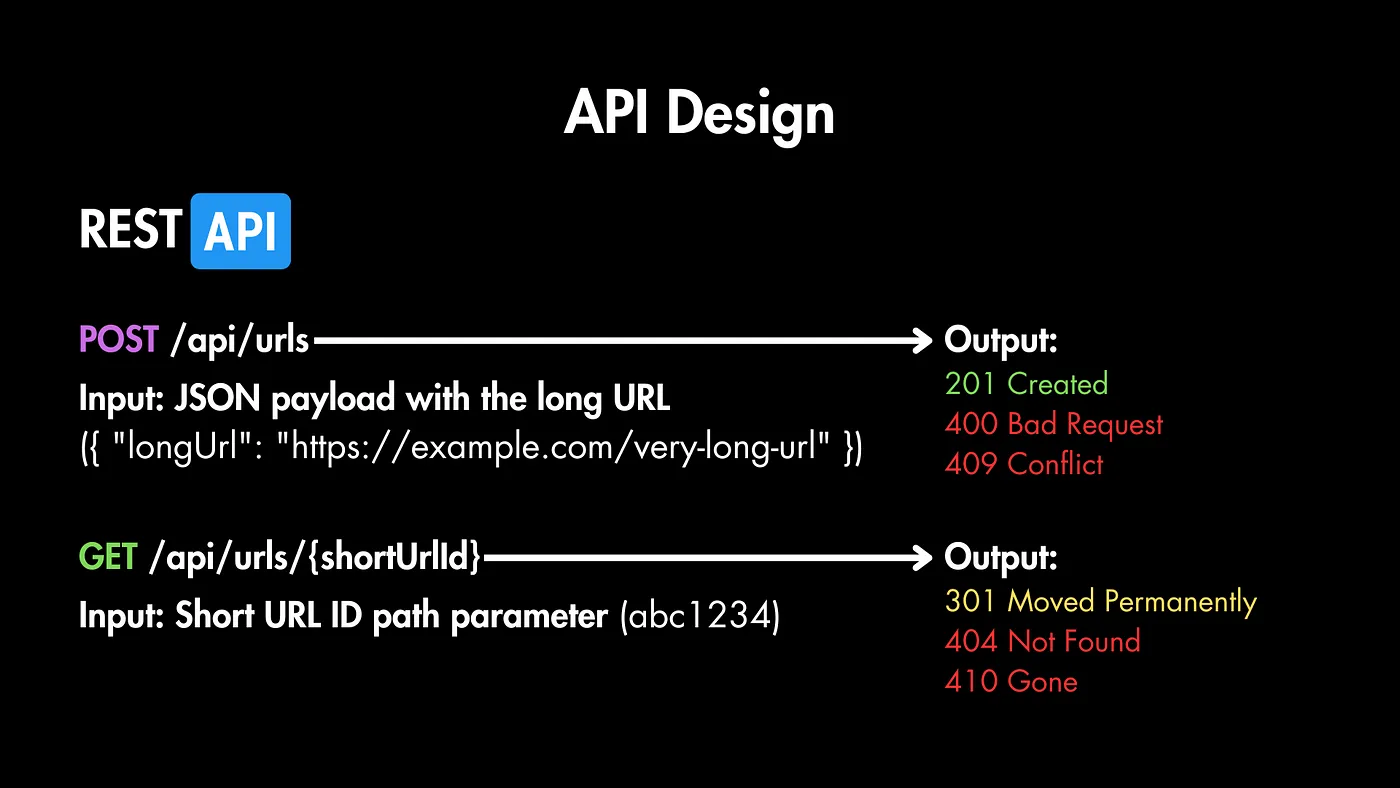
کد وضعیت ۳۰۱ به مرورگر دستور میده که اطلاعات رو کش کنه، یعنی اینکه دفعه بعدی که کاربر URL کوتاه رو تایپ کنه، مرورگر به طور خودکار و بدون اینکه به سرور برسه به URL بلند هدایت میشه.
با این حال، اگر میخواهید آنالیز هر درخواست را ردیابی کنید و مطمئن شوید که از سیستم شما عبور میکند، به جای آن از کد وضعیت 302 استفاده کنید.
پایگاه داده: ذخیره URL های کوتاه شده
بخش بعدی، لایه پایگاه داده است. این لایه نگاشت (mapped) بین URL های کوتاه و URL های بلند را ذخیره می کند. باید برای عملیات خواندن و نوشتن سریع بهینه شود.
اسکما میتونه ساده باشه: یک کلید اصلی برای شناسه URL کوتاه و فیلدهایی برای URL بلند و احتمالاً دادههای متادیتای ایجاد.
{
"shortUrlId": "3ad32p9",
"longUrl": "https://example.com/very-long-url",
"creationDate": "2024-03-08T12:00:00Z",
"userId": "user123",
"clicks": 1023,
"metadata": {
"title": "Example Web Page",
"tags": ["example", "web", "url shortener"],
"expireDate": "2025-03-08T12:00:00Z"
},
"isActive": true
}
اینجا بیشتر باید به خواندنهایی که از پایگاه داده خواهیم داشت فکر کنیم. اگه معمولا ۱۰۰۰ بار نوشتن در ثانیه داشته باشیم، پس میتونیم فرض کنیم که حداقل ۱۰ تا ۱۰۰.۰۰۰ بار خواندن در ثانیه هم داریم.
در این مورد، ما باید از یه پایگاه داده با عملکرد بالا استفاده کنیم که خواندن و نوشتن سریع رو پشتیبانی کنه. این یعنی که باید به سراغ یه پایگاه داده NoSQL بریم (مثل یه document store مثل MongoDB، یه wide-column store مثل Cassandra، یا یه key-value store مثل DynamoDB) چون این پایگاهها به طور خاص برای مدیریت حجم بالایی از داده طراحی شدن.

یکی از بخشهای کلیدی این سیستم، سرویس کوتاهکننده URL هست. این سرویس URLهای کوتاه رو بدون ایجاد تداخل بین URLهای بلند مختلف که به همون URL کوتاه اشاره میکنن، تولید میکنه.
روشهای مختلفی برای پیادهسازی این سرویس وجود داره؛ در اینجا به چند مورد از اونها اشاره میکنیم:
- تابع درهمسازی (Hashing): یه درهمسازی از URL بلند تولید کنید و بخشی از اون رو به عنوان شناسه استفاده کنید. با این حال، درهمسازی میتونه منجر به تداخل بشه.
- شناسههای خود-افزاینده (Auto-increment IDs): از یه شناسه خود-افزاینده پایگاه داده استفاده کنید و اون رو به یه رشته کوتاه کدگذاری کنید. این کار منحصربهفرد بودن رو تضمین میکنه ولی ممکنه قابل پیشبینی باشه.
- الگوریتم سفارشی: یه الگوریتم سفارشی برای تولید شناسههای منحصربهفرد با ترکیبی از کاراکترها طراحی کنید تا از منحصربهفرد بودن و غیرقابل پیشبینی بودن اطمینان حاصل کنید.
برای مثال، برای اجتناب از تداخل، یه راه خیلی ساده وجود داره - ما میتونیم تمام کلیدهای احتمالی با ۷ کاراکتر رو تولید کنیم و اونها رو به عنوان کلید در یه پایگاه داده ذخیره کنیم، جایی که کلید، URL تولید شده و مقدار، یه مقدار بولین (درست یا غلط) باشه؛ اگه مقدار درست باشه، یعنی این URL قبلاً استفاده شده، و اگه غلط باشه، میتونیم از این URL برای ایجاد یه نگاشت (mapped) جدید استفاده کنیم.
بنابراین، هر وقت کاربری درخواست تولید کلید میکنه، میتونیم یه URL از این پایگاه داده پیدا کنیم که در حال حاضر استفاده نمیشه و اون رو به URL بلند موجود در بدنه درخواست نگاشت (mapped) کنیم.
فکر میکنید در این مورد از یه پایگاه داده SQL یا NoSQL استفاده کنیم؟ سناریویی رو در نظر بگیرید که دو کاربر درخواست کوتاه کردن URL بلند خودشون رو بدن، و هر دوی اونها به همون کلید از این پایگاه داده نگاشت (mapped) پیدا کنن.
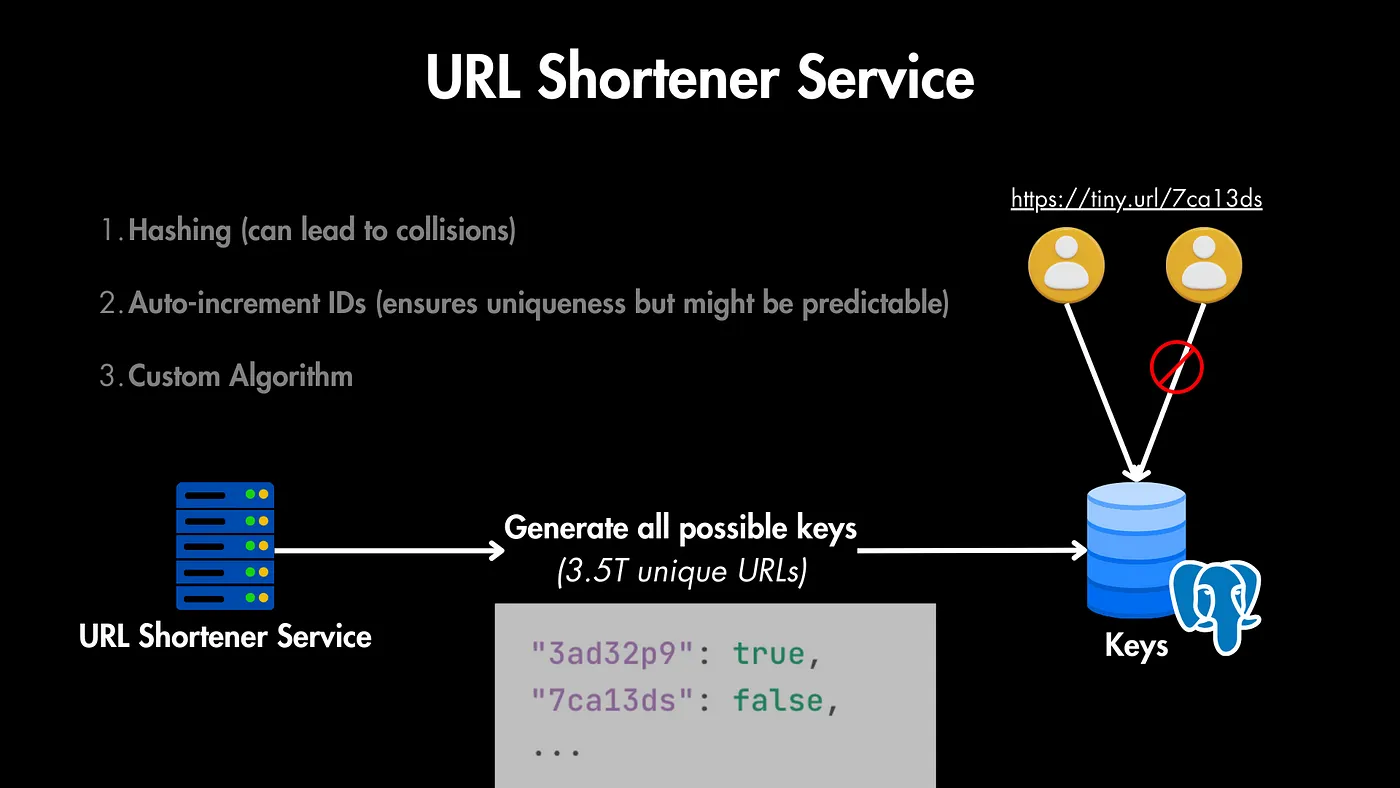
در این مورد، URL به یکی از درخواستهای اونها نگاشت (mapped) پیدا میکنه و اون یکی خراب میشه. پس ما از SQL استفاده میکنیم چون با ویژگیهای ACID همراهه. ما میتونیم برای هر نشست (session) یه تراکنش (transaction) ایجاد کنیم تا این مراحل رو به صورت جداگانه انجام بدیم، و در این صورت با چنین مشکلاتی روبرو نخواهیم شد.
در دسترس بودن بالا و کم تأخیر
سیستم فعلی ما به طور واضح قادر نخواهد بود تا ترافیک ۱۰۰۰ URL در ثانیه رو مدیریت کنه.
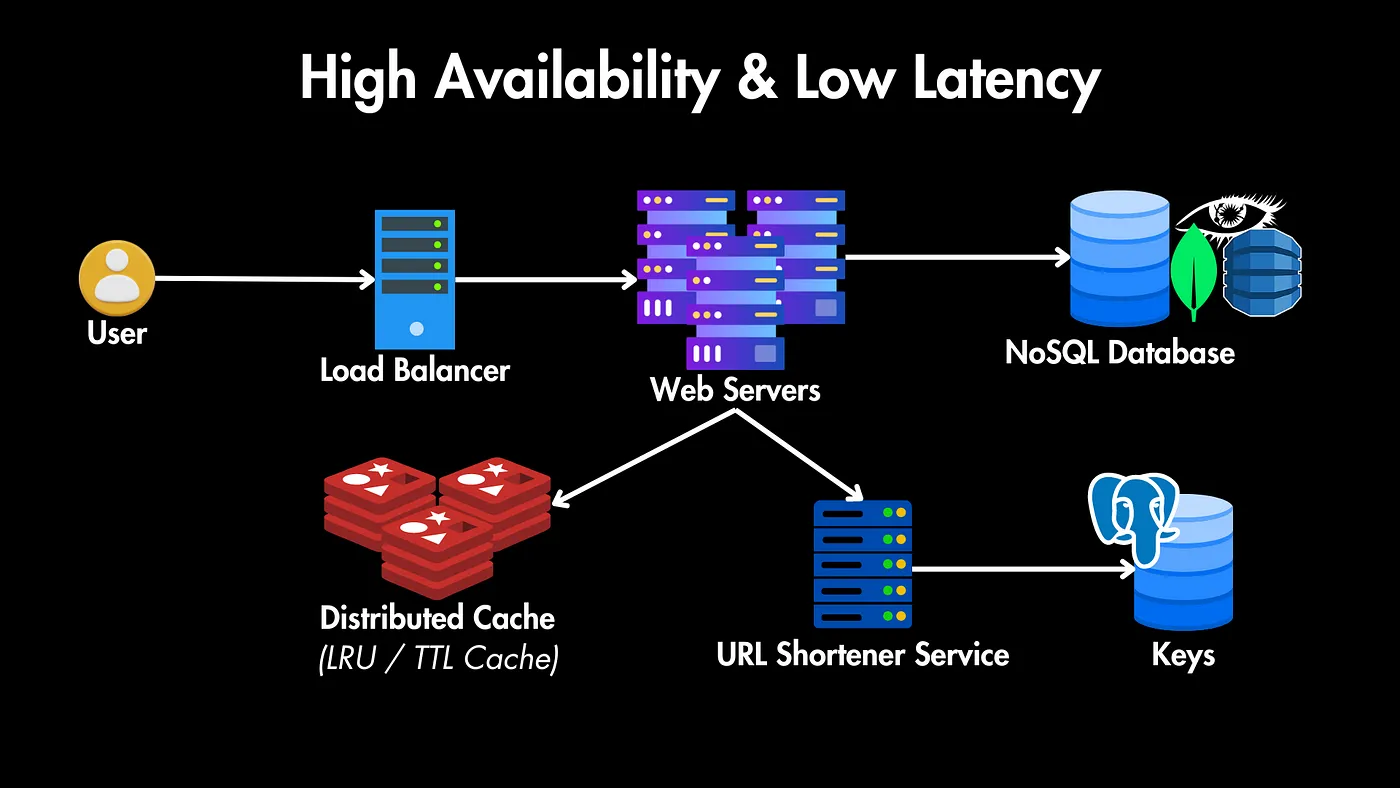
مقیاس پذیری با کش (Caching)
برای مقیاسپذیری بیشتر، اول نیاز به یه لایه کش (مثل Redis) داریم تا URLهای محبوب رو برای بازیابی سریع در یه کش داخل حافظه با ابزاری مثل Redis ذخیره کنیم.
با توجه به اینکه ممکنه بعضی از URL ها خیلی بیشتر از بقیه مورد دسترسی قرار بگیرن، ما به یه سیاست اخراج (eviction policy) نیاز داریم که اولویت رو به آیتمهای با دسترسی بیشتر بده. دو سیاست اخراج کش مناسب برای این سناریو عبارتند از:
-
سیاست اخراج LRU (کمترین استفاده اخیر): این سیاست ابتدا کمترین موارد استفاده شده اخیر رو حذف میکنه. این سیاست برای یه کوتاهکننده URL موثر هست چون تضمین میکنه که کش URLهایی رو که به تازگی و بیشتر بهشون دسترسی پیدا شده در دسترس نگه داره، که میتونه به طور قابل توجهی زمان دسترسی به لینکهای محبوب رو کاهش بده.
-
سیاست اخراج مبتنی بر زمان انقضاء (TTL): این سیاست یه زمان انقضاء مشخص رو به هر ورودی کش اختصاص میده. وقتی زمان انقضای یه ورودی به اتمام برسه، از کش حذف میشه. این سیاست میتونه برای سرویسهای کوتاهکننده URL برای مدیریت کش URLهایی که فقط برای مدت کوتاهی محبوب هستن، مفید باشه.
مقیاس پذیری پایگاه داده: ترکیب تکثیر (Replication) و پارتیشنبندی (Sharding)
برای اطمینان از در دسترس بودن بالا، تحمل خطا و مقیاسپذیری پایگاه داده، باید استراتژیهای تکثیر و پارتیشنبندی رو پیادهسازی کنیم.
با توجه به اینکه مجموعه ۷ کاراکتری ما ۳.۵ تریلیون URL منحصر به فرد داره، میتونیم از پارتیشنبندی مبتنی بر کلید برای توزیع یکنواخت رکوردهای URL در سراسر چندین پارتیشن (shard) استفاده کنیم.
فرض کنیم ما اون رو بین ۳ پارتیشن توزیع میکنیم، هر پارتیشن تقریباً ۱.۱۶ تریلیون URL رو ذخیره میکنه. این با افزایش تعداد URLها، مقیاسپذیری رو تضمین میکنه.
همچنین میتونیم تکثیر استاد-فرعی (master-slave) رو در داخل هر پارتیشن پیادهسازی کنیم تا در دسترس بودن بالا و تحمل خطا رو تضمین کنیم. این تنظیم به بازیابی سریع در صورت خرابی گرهها (node failure) کمک میکنه.
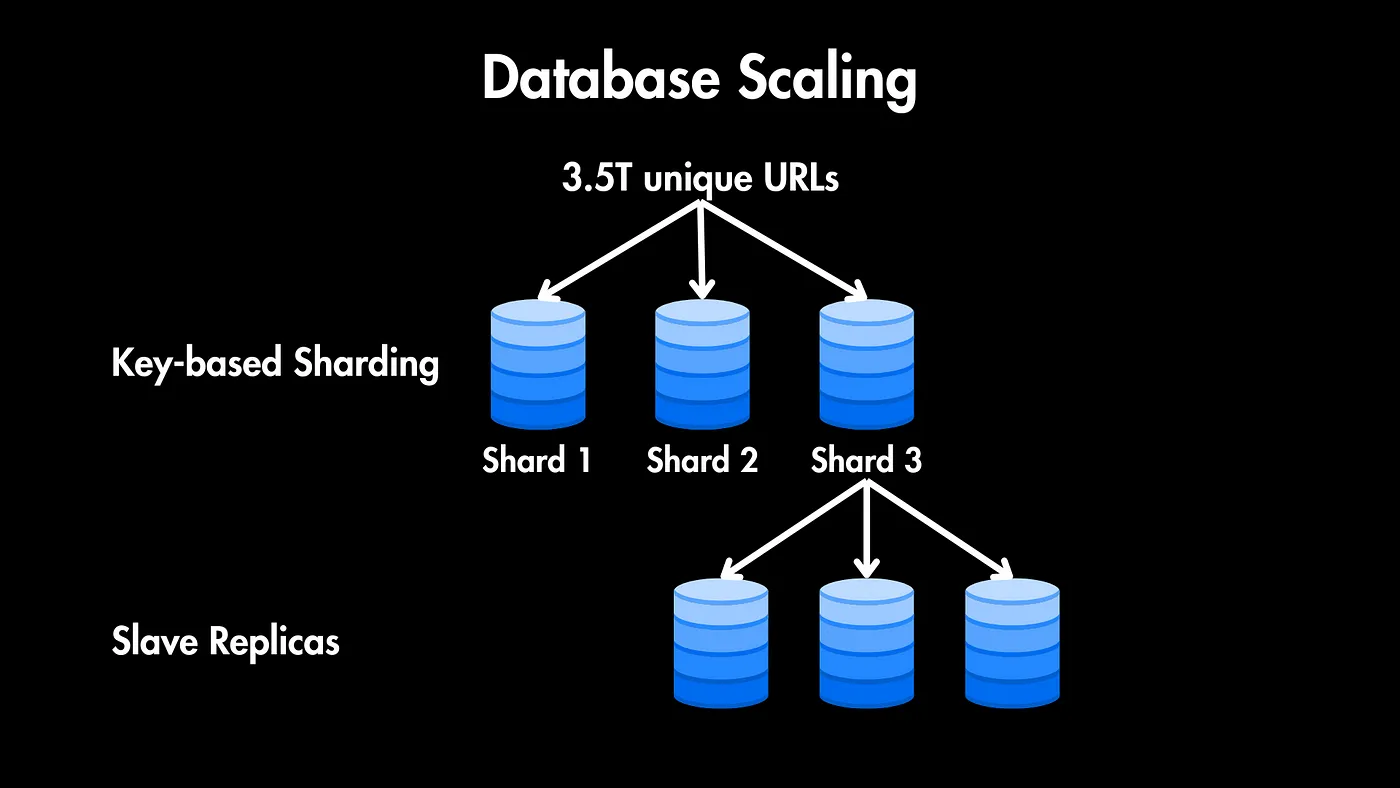
به صورت اختیاری، اگه سرویس برای یه پایگاه کاربری جهانی در نظر گرفته شده، میتونیم پارتیشنبندی و تکثیر جغرافیایی رو در نظر بگیریم تا تأخیر رو کم کنیم و تجربه کاربری رو در مناطق مختلف بهبود بدیم.
این ترکیب به سرویس اجازه میده تا حجم زیادی از کوتاهسازی و هدایت مجدد URL رو با کمترین خرابی و زمان پاسخگویی سریع مدیریت کنه.
نکات امنیتی
در اینجا چند نکته امنیتی برای سرویس ما وجود داره که باید به خاطر داشته باشیم:
-
اعتبارسنجی ورودی: بیایید هر URL ای که کاربر ارسال میکنه رو sanitize کنیم. ما باید پروتکلهای معتبر (HTTP، HTTPS و غیره) رو بررسی کنیم و مطمئن بشیم که URL به خوبی فرمتبندی شده باشه. این کار به جلوگیری از حملات تزریق (injection attacks) کمک میکنه.
-
محدود کردن نرخ (Rate Limiting): میتونیم با محدود کردن تعداد درخواستهایی که یک منبع واحد میتونه ارسال کنه، از سرویس خودمون در برابر حملات DDoS محافظت کنیم. برای این کار میتونیم از الگوریتم token bucket استفاده کنیم.
-
مانیتورینگ و لاگگیری: یه سیستم لاگگیری قدرتمند (مثل ELK stack) ضروریه. این اجازه میده تا لاگها رو برای پیدا کردن bottlenecks و فعالیتهای مشکوک تجزیه و تحلیل کنیم و سلامت کلی سیستم رو تضمین کنیم.
-
پیچیدهسازی (Obfuscation): ما نمیخوایم URLهای کوتاه قابل پیشبینی داشته باشیم. برای اینکه از حدس زدن لینکهای معتبر توسط مهاجمان جلوگیری کنیم، بیایید کمی تصادفی بودن به الگوریتم تولید خودمون اضافه کنیم.
-
انقضای لینک: به صورت اختیاری، میتونیم به کاربران اجازه بدیم تا تاریخ انقضا برای URLهای کوتاهشده خودشون تنظیم کنن. این کار طول عمر لینکهای بالقوه مخرب رو محدود میکنه.
با تشکر از شما که تا آخر مقاله همراه من بودید :)
منابعی که برای آماده سازی این مقاله استفاده شدن:
https://levelup.gitconnected.com/system-design-interview-question-design-url-shortener-c3278a99fc35

 Mahan
Mahan
