تا آخر این مقاله از ام دی کورس با من همراه باشید تا ببینیم اوبر در میان انبوهی از رکوئست ها چطوری نزدیک ترین راننده را با سرعت پیدا میکنه؟
مارچ ۲۰۱۶ - استانبول، ترکیه
چارلز و خانوادهاش رفته بودن یه سفر تفریحی.
اما یه مشکلی داشتن، اونم این بود که تاکسی گیر نمیآوردن. نزدیکترین ایستگاه تاکسی هم ۳ کیلومتر با هتلشون فاصله داشت.
خلاصه که خیلی ناراحت شده بودن.
تا اینکه یهو از پذیرش هتل شنیدن که یه برنامه هست به اسم اوبر که میتونه براشون ماشین بفرسته.
همونجا برنامه رو نصب کردن و دیدن که چقدر راحت میتونن راننده پیدا کنن.
چطوری اوبر رانندههای نزدیک رو پیدا میکنه؟
پیدا کردن رانندگان نزدیک با دقت و مقیاسپذیری بالا، کار سختیه و بریم ببینیم که اوبر چطوری این مشکل را حل کرده:
۱. فهرستبندی موقعیت مکانی (Location Indexing)
پیدا کردن رانندگان نزدیک فقط با استفاده از طول و عرض جغرافیایی دشوار هست، پس، اوبر موقعیتهای مکانی را فهرستبندی یا ایندکس میکنه تا رانندگان نزدیک را بهطور کارآمد پیدا کنه.
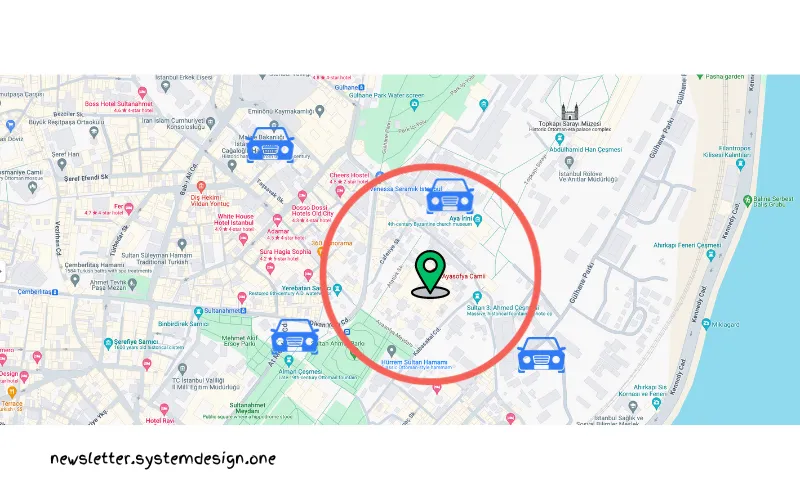
اوبر برای فهرستبندی یا ایندکس موقعیت مکانی از کتابخانهی H3 استفاده میکنه.
H3 یک سیستم فهرستبندی یا ایندکسینگ مکانی سلسلهمراتبی با شکل ششضلعی است که در اوبر ساخته شده.
H3 سطح زمین را به سلولهایی روی یک شبکهی مسطح تقسیم میکنه و به هر سلول یک شناسهی منحصر به فرد با یک عدد صحیح ۶۴ بیتی اختصاص میده.
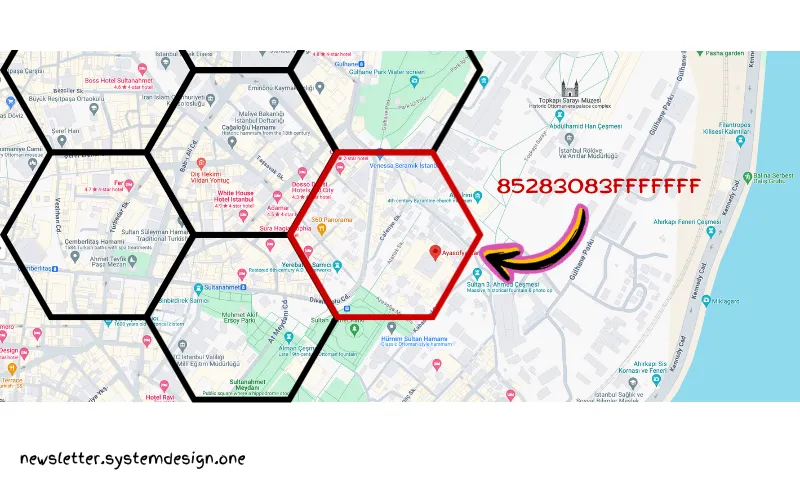
اوبر با شناسایی سلولهای مرتبطی که منطقهی مسافر را پوشش میدن، رانندگان نزدیک رو پیدا میکنه. سپس رانندگان رو در آن سلولها بر اساس زمان تخمینی رسیدن (ETA) مرتبسازی میکنه.
سیستم دیزاین Uber ETA هم خیلی جالبه که توی یک مقاله جداگانه بهش می پردازم
H3 مزایای یک سیستم فهرستبندی یا ایندکسینگ سلسلهمراتبی و یک سیستم شبکهی ششضلعی را ارائه میده.
نحوهی کار H3:
الف) شاخص سلسلهمراتبی (Hierarchical Index)
برای پیدا کردن دقیق رانندگان نزدیک، به شاخص کوچکترین ناحیهی ممکن نیاز هست. به عبارت دیگه، دقت دادهی بالا (high data resolution) ضروری است.
یک سلول کوچک دقت دادهی بالا (high data resolution) رو فراهم میکنه. اما با تعداد زیاد سلولهای کوچکتر، هزینههای ذخیرهسازی افزایش مییابد.
در حالی که سلولهای بزرگتر، جزئیات دادهها رو پنهان می کنن.
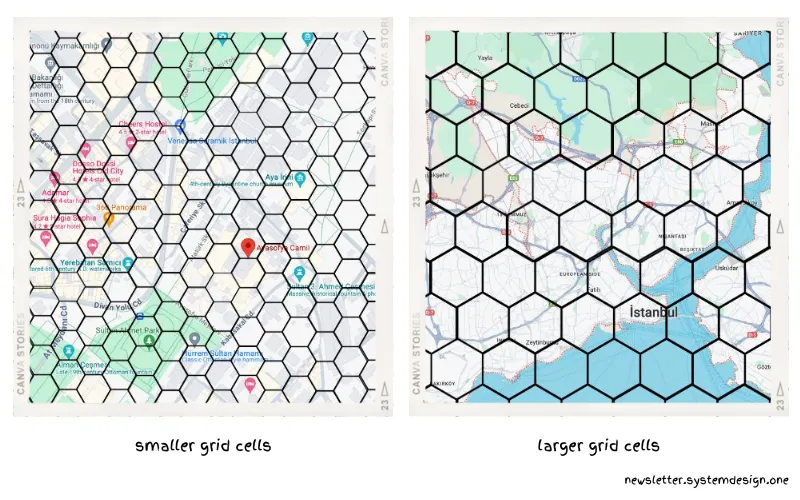
بنابراین، اوبر یک شبکهی سلسلهمراتبی ایجاد کرد و سلولهای ششضلعی کوچکتر رو به عنوان زیرمجموعهای از سلولهای ششضلعی بزرگتر تعریف کرد.
یک شبکهی سلسلهمراتبی امکان فشردهسازی دادهها رو فراهم میکنه. زیرا مناطق با جزئیات کمتر با سلولهای کمتری نشان داده میشن. در حالی که مناطق با جزئیات بیشتر با سلولهای زیادی نشان داده میشن.
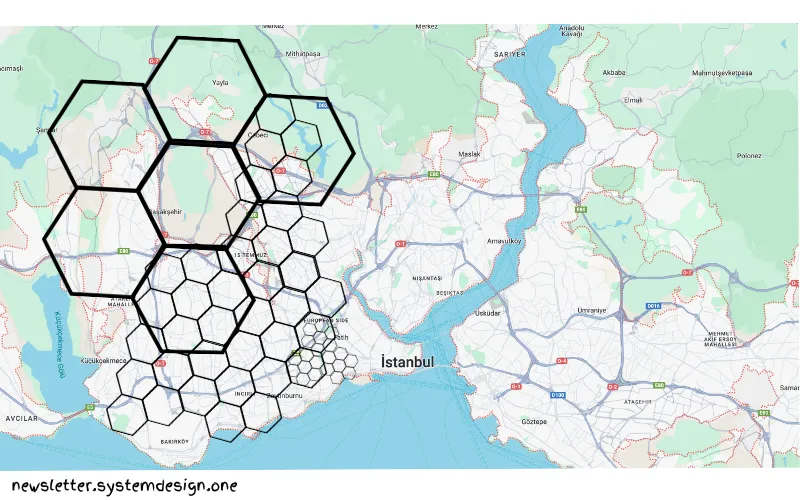
همچنین، تغییر دقت داده با یک شبکهی سلسلهمراتبی آسانتر شد. زیرا شناسهی سلولهای فرزند میتونه برای یافتن سلولهای اجدادی(ancestor) کوتاه بشه.
اوبر یک شبکهی جهانی در H3 با ۱۲۲ سلول پایه ایجاد کرد. با این حال، ۱۲ مورد از ۱۲۲ سلول پایه پنجضلعی هستن، چونکه پوشاندن کامل یک کره (زمین) فقط با ششضلعی امکانپذیر نیست. H3 پنجضلعی را بهعنوان یک ششضلعی بدون یک بخش در نظر میگیره.
علاوه بر این، ششضلعیها به طور کامل تقسیم نمیشن. بنابراین، اوبر یک ششضلعی رو به ۷ ششضلعی با مقدار مشخصی از خطا تقسیم میکنه. و سلولهای فرزند برای مطابقت با شکل ششضلعی والد چرخانده میشن.
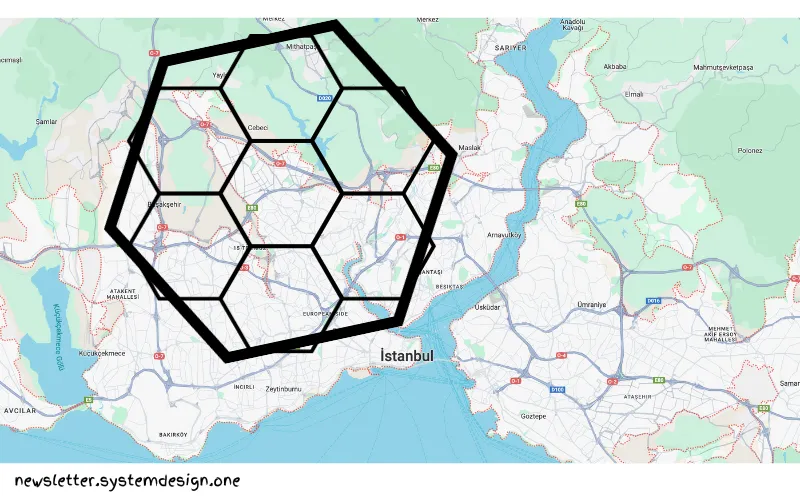
کتابخانهی H3 از ۱۶ نوع دقت داده (data resolution) پشتیبانی میکنه و میتونه ناحیهای به کوچکی ۱ متر مربع را فهرستبندی یا ایندکسینگ کنه.
اوبر از شناسهی سلول (cell identifier) بهعنوان کلید قطعهبندی (sharding key) برای تقسیمبندی H3 استفاده میکنه.
ب) شبکهی ششضلعی (Hexagonal Grid):
برای پیدا کردن رانندگان نزدیک، اوبر به فاصلهی بین سلولها نیاز داره. میشه از اشکال مختلفی مثل مثلث، مربع و ششضلعی برای ساختن شبکه استفاده کرد.
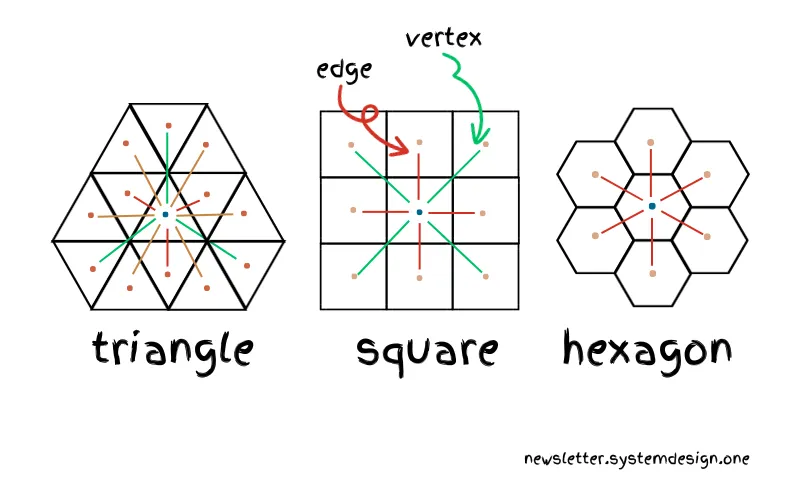
اما H3 از شکل ششضلعی برای سلولها استفاده میکنه، چون اندازهگیری فاصلهی بین دو سلول رو آسونتر میکنه. چونکه هر سلول همسایه با فاصلهای یکسان از مرکز سلول دیگه قرار داره. این باعث سادهتر شدن اندازهگیری فاصله میشه.
در حالی که هر مثلث سه همسایه با فاصلهی متفاوت و هر مربع دو همسایه با فاصلهی متفاوت داره. چونکه برخی از همسایهها یک ضلع مشترک و برخی یک راس مشترک دارن. بنابراین اندازهگیری فاصله بین سلولها در مثلث و مربع نیازمند ضرایب اضافیه.
ج) الگوریتمهای سلسلهمراتبی (Hierarchical Algorithms):
H3 از یک تابع فهرستبندی (indexing function) برای یافتن کارآمد سلولها در شبکه پشتیبانی میکنه. این تابع طول و عرض جغرافیایی و دقت داده رو دریافت کرده و شناسهی سلول رو برمیگردونه.
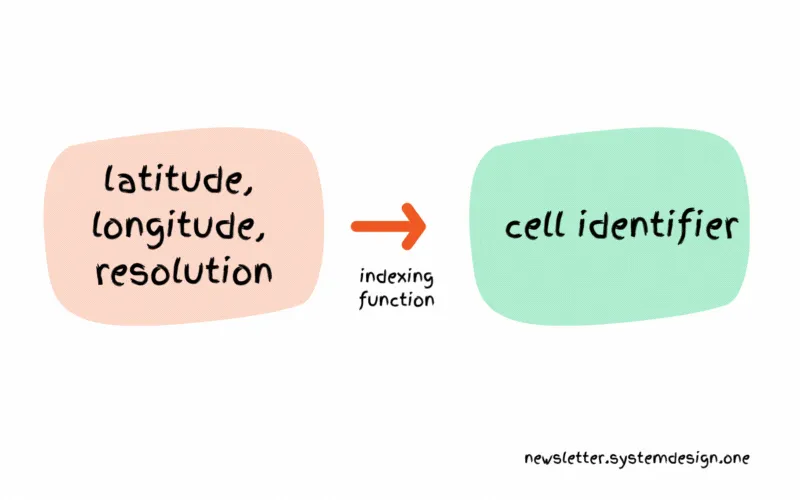
H3 با استفاده از تابع kRing سلولهای همسایه را در اطراف یک سلول خاص پیدا میکنه.
علاوه بر این، H3 از عملیات بیتبهبیت با زمان ثابت (constant-time bitwise operations) برای کوتاه کردن شاخص سلول استفاده میکنه. این امر تغییر بین دقتهای داده رو آسون میکنه.
۲. ذخیرهسازی موقعیت مکانی (Location Storage)
برنامهی هر راننده، هر چند ثانیه یک بار موقعیت مکانی خودش رو به سرور ارسال میکنه. اما سیگنالهای GPS به دلیل ضعیف بودن شبکه ممکنه ناقص و پراکنده باشن.
یافتن رانندگان نزدیک، نیازمند موقعیت مکانی دقیقه. بنابراین، از مطابقت نقشه (map matching) استفاده میشه.
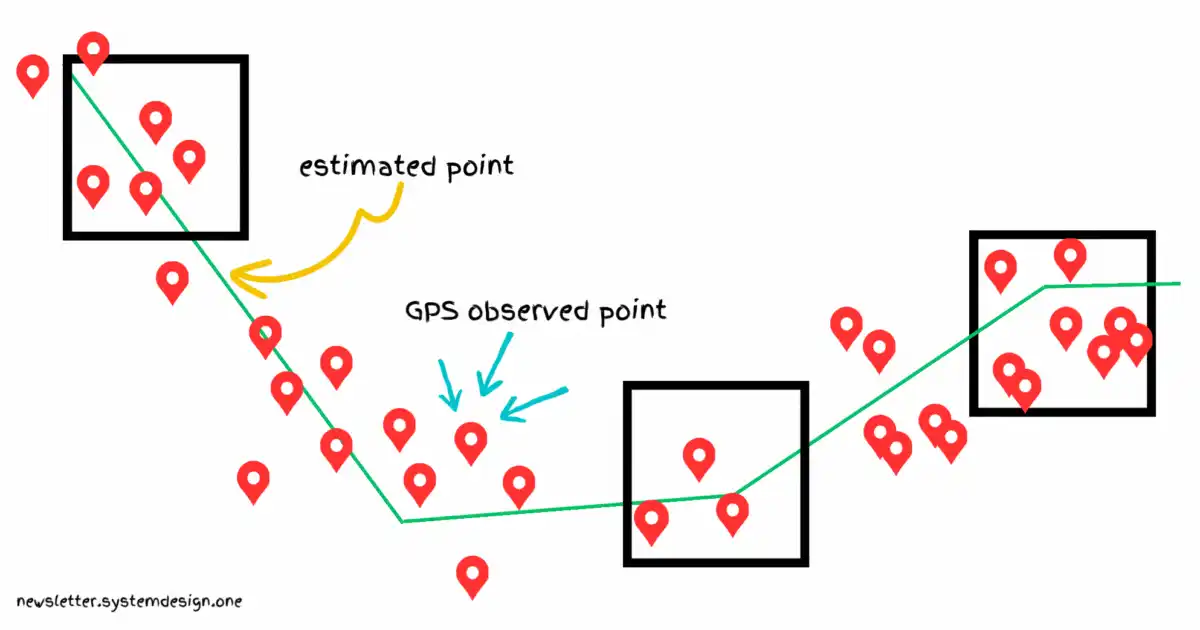
مطابقت نقشه(Map matching)، سیگنالهای خام (raw) GPS رو به بخشهای واقعی جاده (actual road segments) تبدیل میکنه.
اوبر برای ذخیرهسازی بلندمدت موقعیتهای مکانی خام (raw)، از Apache Cassandra استفاده میکنه. Apache Cassandra یک پایگاه دادهی توزیعشدست. اما Cassandra برای عملیات نوشتن بهینه شده.
بنابراین، اوبر یک لایهی کش (cache) با نام Redis روش اضافه میکنه تا بار عملیات خواندن رو کم کنه.
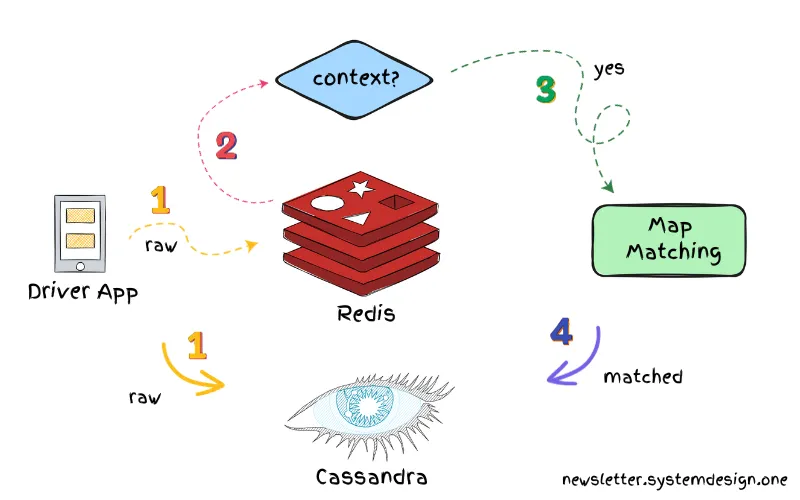
Redis موقعیتهای مکانی اخیر هر راننده را ذخیره میکنه. همچنین، دادههای کافی برای انجام مطابقت نقشه رو تو خودش نگه میداره.
بعد دادههای مطابق با نقشه، در یک اسکیمای جداگانه روی Cassandra ذخیره میشن.
۳. مقیاسپذیری (Scalability)
برای مقیاسپذیری سرویسها، از ringpop استفاده میکنن.
Ringpop یک ماژول consistent hash ring متعلق به اوبر است که از gossip protocol استفاده میکنه. این ماژول در سرویسهای کاربردی جاسازی شده.
اوبر از پروتکل gossip برای ردیابی لیست membership و وضعیت سلامت سرورها استفاده میکنه.
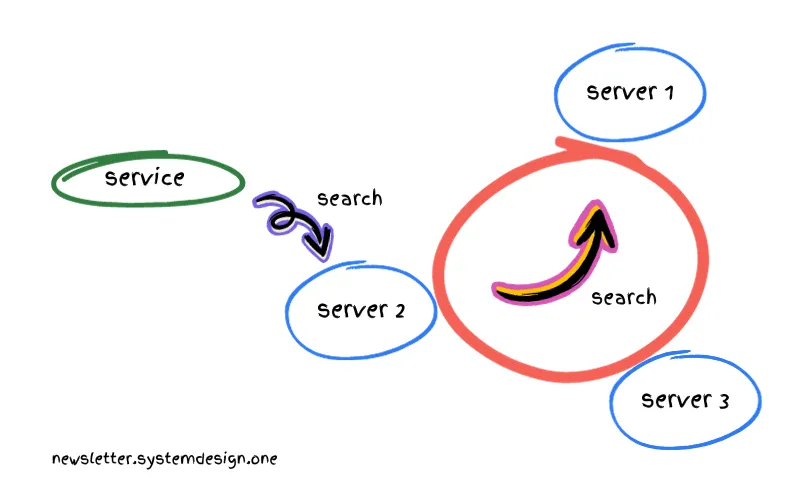
جستجو در consistent hash ring، درخواست رو به سرور مسئولش هدایت میکنه. اوبر با اضافه کردن سرورهای بیشتر، write ها رو مقیاسبندی میکنه. در حالی که read ها با اضافه کردن نسخههای پشتیبان(replicas) مقیاسبندی میشن.
اوبر برای برقراری ارتباط کارآمد از Thrift over Remote Procedure Calls (RPC) استفاده میکنه.
علاوه بر این، برای دستیابی به در دسترسبودن بالا از طریق تلاشهای مجدد، هر سرویس ایدمپوتنت (idempotent) نگه داشته میشه.
اوبر یک مرکز دادهی پشتیبان اجرا میکنه و در صورت خرابی مرکز دادهی فعال، ترافیک رو بهش هدایت میکنه.
برای بهترین تجربهی مسافر، پیدا کردن رانندگان نزدیک با دقت بالا ضروریه. روش فعلی به اوبر این امکان رو داده که مقیاسبندی خودش رو به ۱ میلیون درخواست در ثانیه برسونه.
خب خیلی ممنون که تا اینجای مقاله همراه من بودید و امیدوارم براتون مفید بوده باشه. در ادامه بریم با منابعی که برای آماده سازی این پست استفاده شدند آشنا بشیم:
لینک هایی که کنارشون ستاره دارن ویدیو های یوتیوب از کانال
Uber Engineering هستند و بهتون پیشنهاد میکنم حتما بهشون سر بزنید


 Mahan
Mahan