Load Balancer ها در معماری وب نقشی اساسی دارن.
چونکه اجازه میدن بار بین مجموعه ای از backendها توزیع بشه. این باعث مقیاس پذیری بیشتر خدمات میشه و در نهایت سرویس با
داشتن load balancer تشخیص بده کدوم سرور ترافیک زیادی روشه یا خراب شده و ترافیک را به سرور های آماده به کار منتقل کنه.
توی این پست قرار با استفاده از Golang یک لود بالانسر ایجاد کنیم.
لود بالانسر ما چطوری کار میکنه؟
استراتژی های مختلفی برای ساخت لودبالانسر وجود داره که چطوری ترافیک را در بین بکند ها تقسیم کنند.
به طور کلی دو دسته از این الگوریتمها وجود دارد:
✅ استاتیک (Static):
- Round Robin
- Sticky Round Robin
- Hash
- Weighted Round Robin
✅ پویا (Dynamic):
- Least Connections
- Least Response Time
بیایید به هر الگوریتم با جزئیات بیشتری نگاه کنیم:
👈 Round Robin:
درخواستها به صورت متوالی در بین گروهی از سرورها توزیع میشوند. هیچ تضمینی وجود ندارد که چندین درخواست از یک کاربر به یک
نمونه (instance) برسند.
👈 Sticky Round Robin:
یک جایگزین بهتر برای Round Robin. درخواستهای مختلف از یک کاربر به یک نمونه (instance) واحد میرسند.
👈 Hash-Based:
این الگوریتم درخواستها را بر اساس هش مقدار کلید توزیع میکند. کلید میتواند آدرس IP یا URL درخواست باشد.
👈 Weighted Round Robin:
هر سرور یک مقدار وزن دریافت میکند. این مقدار، نسبت ترافیک را تعیین میکند. سرورهایی با وزن بالاتر، ترافیک بیشتری دریافت
میکنند. این الگوریتم برای تنظیماتی که سرورهایی با سطوح ظرفیت مختلف دارند، مناسب است.
👈 Least Connections:
درخواست جدید به نمونه سرور با کمترین تعداد اتصالات ارسال میشود. تعداد اتصالات بر اساس ظرفیت محاسباتی نسبی یک سرور تعیین
میشود.
👈 Least Response Time:
درخواست جدید به سروری با کمترین زمان پاسخ ارسال میشود تا زمان پاسخ کلی به حداقل برسد. این الگوریتم برای مواردی که زمان
پاسخ حیاتی است، مناسب است.
منبع: پست کانال
خب من اینجا از الگوریتم و استراتژی Round Robin استفاده می کنم
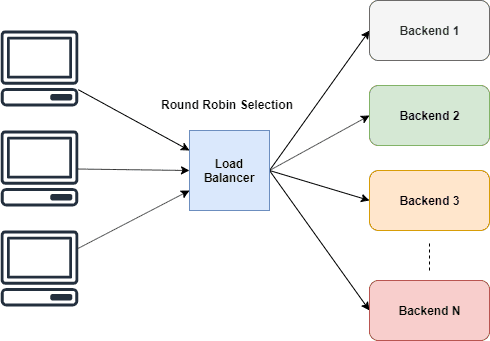
Round Robin
Round Robin در اصطلاح سادس . به worker ها فرصت برابر میده تا به نوبت وظایف خودشون رو انجام بدن.
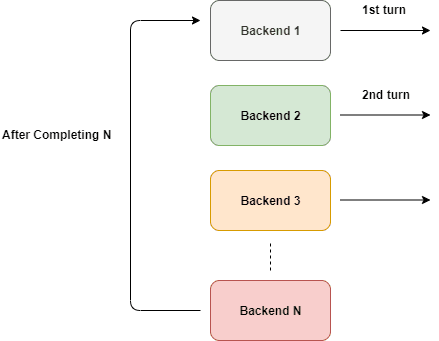
همانطور که در شکل نشون داده شده، این به طور مداوم اتفاق میوفته. اما نمی تونیم این رو مستقیماً استفاده کنیم، نه؟
اگر یک سرور بکند داون/down بشه، احتمالاً نمیخوایم ترافیک رو بهش هدایت کنیم. بنابراین، این نمیتونه مستقیماً استفاده بشه مگر اینکه برخی شرایط روش اعمال بشه. باید ترافیک رو فقط به سرورهایی که روشن و در حال اجرا هستن، هدایت کنیم.
بیایید چند ساختار را تعریف کنیم
پس از بازنگری در طرح، اکنون میدونیم که نیاز به راهی برای track تمام جزئیات مربوط به Backend داریم. باید پیگیری کنیم که آیا در دسترسه یا خاموش و همچنین URL رو هم track کنیم.
میتونیم خیلی ساده یه struct مثله این رو تعریف کنیم تا بکند هامون رو نگه داره:
type Backend struct {
URL *url.URL
Alive bool
mux sync.RWMutex
ReverseProxy *httputil.ReverseProxy
}
نگران نباشید جلو تر به فیلد های Backend می پردازم.
حالا نیاز داریم راهی برای track تمام بکند ها در لود بالانسر خودمون پیدا کنیم، برای این کار میتونیم به سادگی از یه Slice استفاده کنیم. و همچنین یک متغیر شمارنده. ما میتونیم اون ها رو در ServerPool تعریف کنیم
type ServerPool struct {
backends []*Backend
current uint64
}
استفاده از ReverseProxy
همانطور که قبلاً تعریف کردیم ، هدف اصلی لود بالانسر هدایت ترافیک به سرورهای مختلف و بازگشت نتایج به کلاینت اصلیه.
طبق مستندات Go:
ReverseProxy یک Handler HTTP است که درخواست ورودی را می گیرد و آن را به سرور دیگری ارسال می کند و پاسخ را به کلاینت پروکسی می کند.
این دقیقاً همون چیزیه که میخوایم. نیازی به اختراع دوباره چرخ نیست. میتونیم درخواست های اصلیمون رو از طریق ReverseProxy منتقل کنیم.
u, _ := url.Parse("http://localhost:8080")
rp := httputil.NewSingleHostReverseProxy(u)
// initialize your server and add this as handler
http.HandlerFunc(rp.ServeHTTP)
با استفاده از** httputil.NewSingleHostReverseProxy(url)** میتونیم یه ReverseProxy رو راه اندازی کنیم که درخواستها را به URL ارسال شده ارسال کنه. در مثال بالا، همه درخواستها به localhost:8080 منتقل میشن و نتایج به کلاینت اصلی ارسال میشن.
اگر نگاهی به متد ServeHTTP بندازیم، signature اش مشابه signature یک Handler HTTP است، به همین دلیل میتونیم اون رو به HandlerFunc در http پاس بدیم.
میتونید مثال های بیشتر رو توی docs ببینید.
برای لود بالانسر سادمون میتونیم ReverseProxy رو با URL مرتبط در Backend راهاندازی کنیم تا ReverseProxy درخواستهای ما را به URL هدایت کند.
فرایند انتخاب
ما باید سرورهایی که در حال حاضر غیرفعال هستن رو در بارگذاری بعدی درخواست ها رد کنیم. اما برای انجام این کار به راهی برای شمارش نیاز داریم.
چندین کلاینت به لود بالانسر متصل میشن و وقتی که هر یک از این کلاینت ها از peer بعدی درخواست میکنه تا ترافیک رو منتقل کنه ، ممکن است شرایط race یا مسابقه مانندی رخ بده. برای جلوگیری ازش، میتونیم Pool سرور رو با یک رمزنگاری قفل کنیم. اما این کار بیش از حد ضروری است، علاوه بر این ما نمیخوایم Pool سرور رو به طور کلی قفل کنیم. ما فقط میخوایم شمارنده را به یک واحد افزایش بدیم.
برای برآورده کردن این الزامات، راه حل ایده آل اینه که این افزایش را به صورت اتمیک انجام بدیم. و Go این کار رو به خوبی از طریق پکیج atomic پشتیبانی می کنه.
func (s *ServerPool) NextIndex() int {
return int(atomic.AddUint64(&s.current, uint64(1)) % uint64(len(s.backends)))
}
در اینجا، ما به صورت اتمی مقدار فعلی رو یک بار افزایش میدیم و شاخص را با طول slice تغییر میدیم. پس در نتیجه مقدار همیشه بین 0 و طول slice هستش. در نهایت، ما به index خاصی علاقه مندیم، نه تعداد کل.
انتخاب یک بکند فعال/زنده
میدونیم که درخواست های ما به طور چرخشی برای هر backend ارسال میشن. تنها کاری که باید بکنیم این که که موارد غیر فعال/مرده رو حذف کنیم.
GetNext() همیشه یک مقدار رو برمیگردونه که بین 0 و طول slice محدود شده. در هر نقطه، ما یک peer بعدی دریافت می کنیم و اگه فعال/زنده نباشه باید در slice به صورت چرخشی جستجو کنیم.
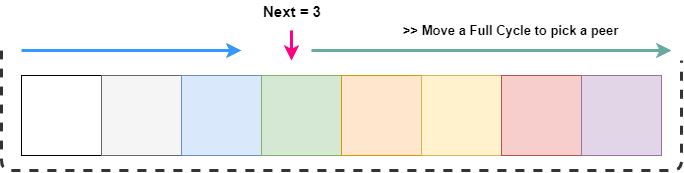
همانطور که در تصویر بالا نشون داده شده، ما میخوایم از next تا entire list پیمایش کنیم، که میتونه به سادگی با پیمایش **next + length **انجام بشه. اما برای انتخاب یک index، میخوایم اون ها رو بین طول slice محدود کنیم. این کار به راحتی با عمل mod انجام میشه.
بعد از پیدا شدن یک backend کارآمد در طول جستجو، اون رو به عنوان backend فعلی مشخص می کنیم.
در زیر می توانید کد برای عملیات فوق رو ببینید:
// GetNextPeer returns next active peer to take a connection
func (s *ServerPool) GetNextPeer() *Backend {
// loop entire backends to find out an Alive backend
next := s.NextIndex()
l := len(s.backends) + next // start from next and move a full cycle
for i := next; i < l; i++ {
idx := i % len(s.backends) // take an index by modding with length
// if we have an alive backend, use it and store if its not the original one
if s.backends[idx].IsAlive() {
if i != next {
atomic.StoreUint64(&s.current, uint64(idx)) // mark the current one
}
return s.backends[idx]
}
}
return nil
}
از شرایط race/مسابقه در ساختار Backend اجتناب کنید
یک مسئله جدی وجود داره که باید در نظر گرفته بشه. ساختار Backend ما دارای یک متغیره که میتونه توسط goroutine های مختلف همزمان تغییر داده بشه یا بهشون دسترسی پیدا کنه.
ما میدونیم که بیشتر goroutine ها روی متغیر بیشتر از نوشتن عملیات خواندن انجام میدن. بنابراین، ما RWMutex رو برای سریال سازی دسترسی به Alive انتخاب می کنیم.
// SetAlive for this backend
func (b *Backend) SetAlive(alive bool) {
b.mux.Lock()
b.Alive = alive
b.mux.Unlock()
}
// IsAlive returns true when backend is alive
func (b *Backend) IsAlive() (alive bool) {
b.mux.RLock()
alive = b.Alive
b.mux.RUnlock()
return
}
بیایید requests ها را لود بالانس کنیم
با تمام زمینه هایی که آماده کردیم ، میتونیم روش ساده زیر رو برای لود بالانس درخواست استفاده کنیم. فقط زمانی شکست میخوره که تمام backend های ما آفلاین باشن.
// lb load balances the incoming request
func lb(w http.ResponseWriter, r *http.Request) {
peer := serverPool.GetNextPeer()
if peer != nil {
peer.ReverseProxy.ServeHTTP(w, r)
return
}
http.Error(w, "Service not available", http.StatusServiceUnavailable)
}
این روش رو میشه به سادگی به عنوان یک HandlerFunc به سرور http منتقل کرد.
server := http.Server{
Addr: fmt.Sprintf(":%d", port),
Handler: http.HandlerFunc(lb),
}
ترافیک را فقط به بکند های سالم منتقل کنید
مشکل جدی در لود بالانسر فعلی ما وجود داره. نمیدونیم که یک سرور بکند سالمه یا نه. برای فهمیدن این موضوع باید یک سرور بکند رو امتحان کنیم و ببینیم آیا فعاله .
این کار رو میتونیم به دو روش انجام بدیم:
- فعال: در حین انجام درخواست فعلی، اگر سرور بکند انتخاب شده پاسخگو نباشد، اون رو به عنوان غیرفعال علامت بزنیم.
- غیر فعال: میتونیم سرورهای بکند رو در بازههای زمانی ثابت پینگ کنیم و وضعیتشون رو بررسی کنیم.
به طور فعال بکند های سالم بررسی می شود
ReverseProxy در صورت وقوع هرگونه خطایی، یک تابع بازگشتی به نام ErrorHandler رو فعال میکنه. ما میتونیم ازش برای تشخیص هرگونه شکست استفاده کنیم. در اینجا پیادهسازیش اومده:
proxy.ErrorHandler = func(writer http.ResponseWriter, request *http.Request, e error) {
log.Printf("[%s] %s\n", serverUrl.Host, e.Error())
retries := GetRetryFromContext(request)
if retries < 3 {
select {
case <-time.After(10 * time.Millisecond):
ctx := context.WithValue(request.Context(), Retry, retries+1)
proxy.ServeHTTP(writer, request.WithContext(ctx))
}
return
}
// after 3 retries, mark this backend as down
serverPool.MarkBackendStatus(serverUrl, false)
// if the same request routing for few attempts with different backends, increase the count
attempts := GetAttemptsFromContext(request)
log.Printf("%s(%s) Attempting retry %d\n", request.RemoteAddr, request.URL.Path, attempts)
ctx := context.WithValue(request.Context(), Attempts, attempts+1)
lb(writer, request.WithContext(ctx))
}
در اینجا از قدرت توابع بستهای برای طراحی این ErrorHandler استفاده شده. این امکان رو به ما میده تا متغیرهای خارجی مثل URL سرور رو در روش خود بگیریم. این تابع بررسی میکنه که تعداد درخواست مجدد موجود کمتر از 3 باشد، اگر اینجوری باشه، همان درخواست رو دوباره به همان سرور بکند ارسال میکنیم. دلیل این کار اینکه که ممکنه سرور به دلیل خطاهای موقت درخواستهای شما را رد کنه و ممکنه پس از مدت کوتاهی در دسترس باشه (ممکنه سرور از سوکتها برای پذیرش کلاینت های بیشتر خالی شده باشه). بنابراین، ما یک تایمر قرار دادیم تا تاخیر در درخواست مجدد را برای حدود 10 میلیثانیه به تأخیر بندازه. ما تعداد درخواست مجدد رو با هر درخواست افزایش میدیم.
پس از هر بار تلاش ناموفق، این backend رو به عنوان غیرفعال/down گزارش میدیم.
قدم بعدی اینکه که یک backend جدید رو برای همون درخواست امتحان کنیم. این کار را با نگه داشتن شمارنده تلاش با استفاده از بسته context انجام میدیم. پس از افزایش تعداد تلاشها، اون رو دوباره به لود بالانسر ارسال میکنیم تا یک peer جدید برای پردازش درخواست انتخاب کنه.
حالا ما نمیتونیم این کار رو به طور نامحدود انجام بدیم، پس باید بررسی کنیم که آیا حداکثر تلاش قبل از پردازش بیشتر درخواست انجام شده یا نه.
ما میتونیم به سادگی تعداد تلاشهای موجود در درخواست رو دریافت کنیم و اگر از حداکثر تعداد تجاوز کرده باشه، درخواست رو حذف کنیم.
// lb load balances the incoming request
func lb(w http.ResponseWriter, r *http.Request) {
attempts := GetAttemptsFromContext(r)
if attempts > 3 {
log.Printf("%s(%s) Max attempts reached, terminating\n", r.RemoteAddr, r.URL.Path)
http.Error(w, "Service not available", http.StatusServiceUnavailable)
return
}
peer := serverPool.GetNextPeer()
if peer != nil {
peer.ReverseProxy.ServeHTTP(w, r)
return
}
http.Error(w, "Service not available", http.StatusServiceUnavailable)
}
این پیادهسازی بازگشتیه.
استفاده از context
پکیج context به شما امکان ذخیره داده های مفید در یک درخواست Http رو میده. ما این رو به طور گسترده برای track داده های خاص درخواست مانند تعداد تلاش و تعداد تکرار استفاده کردیم.
ابتدا باید کلیدهایی رو برای context مشخص کنیم. توصیه میشه از کلیدهای non-colliding integer به جای رشته ها استفاده بشه. Go کلمه کلیدی iota رو برای پیاده سازی مقادیر ثابت به صورت افزایشی ارائه میده، هر کدام حاوی یک مقدار منحصر به فرده. این یک راه حل عالی برای تعریف کلیدهای عددیه.
const (
Attempts int = iota
Retry
)
سپس میتونیم مقدار رو همانطور که معمولاً با HashMap انجام میدیم، بازیابی کنیم. مقدار بازگشتی پیش فرض ممکنه به کاربرد بستگی داشته باشه.
// GetAttemptsFromContext returns the attempts for request
func GetRetryFromContext(r *http.Request) int {
if retry, ok := r.Context().Value(Retry).(int); ok {
return retry
}
return 0
}
بررسی های سلامت غیرفعال/Passive
چکهای سلامت Passive به ما امکان بازیابی یا شناسایی بکاندهای غیرفعال/داون/آفلاین رو میدن. ما بهطور دورهای با فواصل زمانی ثابت بکاندها رو برای بررسی وضعیتشون پینگ میکنیم.
برای پینگ، سعی میکنیم یک اتصال TCP برقرار کنیم. اگر بکاند پاسخ بده، اون رو زنده/آنلاین علامتگذاری میکنیم. این روش رو میتونید برای تماس با یک endpoint خاص مانند /status تغییر بدید. مطمئن بشید که پس از برقراری اتصال، اون را ببندید تا بار اضافی در سرور کاهش پیدا کنه. در غیر این صورت، سعی میکنه اتصال رو حفظ کنه و در نهایت منابعش تموم میشن.
// isAlive checks whether a backend is Alive by establishing a TCP connection
func isBackendAlive(u *url.URL) bool {
timeout := 2 * time.Second
conn, err := net.DialTimeout("tcp", u.Host, timeout)
if err != nil {
log.Println("Site unreachable, error: ", err)
return false
}
_ = conn.Close() // close it, we dont need to maintain this connection
return true
}
حالا میتونیم سرورها رو مرور کنیم و وضعیتشون رو مثل کد زیر مشخص کنیم:
// HealthCheck pings the backends and update the status
func (s *ServerPool) HealthCheck() {
for _, b := range s.backends {
status := "up"
alive := isBackendAlive(b.URL)
b.SetAlive(alive)
if !alive {
status = "down"
}
log.Printf("%s [%s]\n", b.URL, status)
}
}
برای اجرای این کار به طور دوره ای میتونیم یک تایمر در Go شروع کنیم. وقتی که یک تایمر ایجاد شد ، به شما امکان میده از طریق یک کانال برای رویداد گوش کنید.
// healthCheck runs a routine for check status of the backends every 20 secs
func healthCheck() {
t := time.NewTicker(time.Second * 20)
for {
select {
case <-t.C:
log.Println("Starting health check...")
serverPool.HealthCheck()
log.Println("Health check completed")
}
}
}
در قطعه کد بالا ، کانال <-t.C هر 20 ثانیه یک مقدار رو برمیگردونه. select اجازه میده تا این رویداد رو تشخیص بده. select تا زمانی که هیچ مورد پیش فرض وجود نداشته باشه ، منتظر اجرای حداقل یک case هست.
در نهایت، این کار رو در یک goroutine جداگانه اجرا کنید.
جمع بندی
در این مقاله چیزهای زیادی رو پوشش دادیم.
- انتخاب Round Robin
- ReverseProxy از کتابخانه استاندارد
- قفلهای متقابل (Mutexes)
- عملیات اتمی (Atomic Operations)
- تابعهای بسته (Closures)
- درخواستهای بازگشتی (Callbacks)
- عملیات انتخاب (Select Operation)
هنوز کارهای زیادی وجود داره که میتونیم برای بهبود لود بالانسرمون انجام بدیم.
برای مثال:
- از یک heap برای مرتب کردن بکند های آنلاین استفاده بشه تا سطح جستجو را کاهش بدیم
- statistics ها را جمع آوری کنید
- پشتیبانی از فایل پیکربندی رو اضافه کنید
- و…
شما میتونید کد لود بالانسر را در این ریپو مشاهده کنید.
ممنون که تا پایان مقاله همراه من بودید 😄
منابع

 Mahan
Mahan
